
Carlos Marquez
jueves, 6 de febrero de 2025 | 7 minutos
Configuración de inteligencia de amenazas, parte 2 (Graylog)
¡Bienvenidos nuevamente a la serie Threat Intel! En este capítulo, nos arremangamos y profundizamos en las potentes funciones de Graylog para optimizar la forma en que maneja y enriquece los datos de registro de PFSense y Suricata. Si está listo para transformar los mensajes de registro sin procesar en información útil, ¡esta guía es para usted!
¿Qué hay en la agenda?
Configuraremos los parámetros esenciales de Graylog para optimizar el análisis de los mensajes de registro entrantes. Al finalizar este análisis en profundidad, tendrá una configuración capaz de:
- Analizar de manera eficiente los registros de PFSense con la ayuda de reglas de canalización.
- Configuración del procesador de ubicación geográfica para asignaciones de puertos y búsquedas de GeoIP, lo que nos proporciona datos enriquecidos y conscientes del contexto.
- Integración de datos de Suricata para una capa adicional de visibilidad de la red.
Los registros son tan valiosos como la información que se puede extraer de ellos. Sin un procesamiento adecuado, los datos críticos pueden permanecer ocultos a simple vista. Al aprovechar las capacidades de Graylog, no solo podrá comprender los datos, sino que también los mejorará, convirtiendo su laboratorio doméstico en un sistema sólido y consciente de las amenazas.
1. Índices
Primero, cree un conjunto de índices para cada tipo de mensaje de syslog que planee conservar. Cada conjunto de índices contiene las configuraciones necesarias para que Graylog cree, administre y complete índices de backend de búsqueda. También maneja la rotación de índices y la retención de datos según sus requisitos específicos.
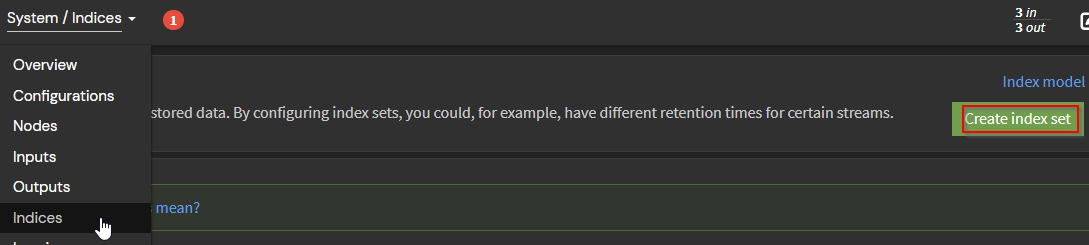
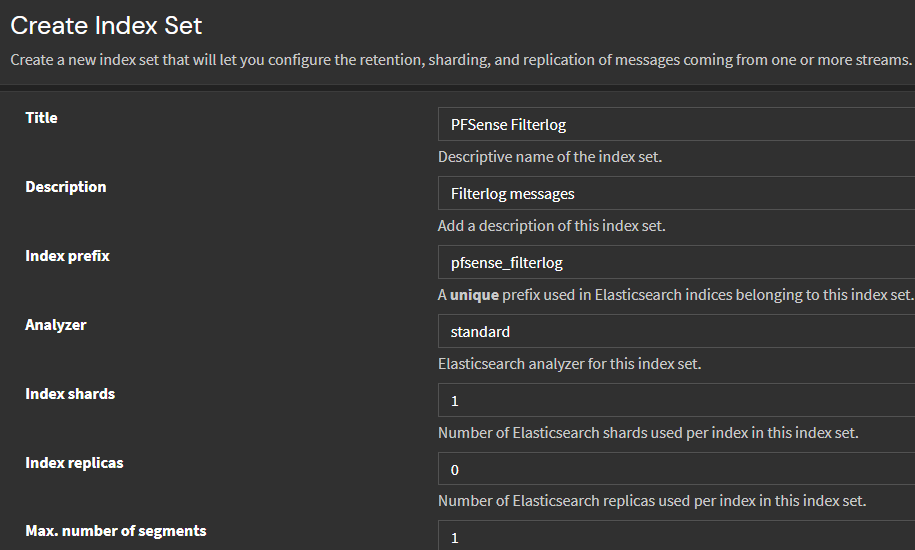
Crearemos 3 conjuntos de índices ya que podemos esperar mensajes de syslog para:
- Eventos generales del servidor PFSense desde el sistema operativo (pfsense_alerts)
- Alertas de suricata (pfsense_suricata)
- Registro de filtros PFSense para eventos PASS y FAIL según reglas de firewall configuradas (pfsense_filterlog)
Cada conjunto de índices se configura con un fragmento que se puede ampliar para lograr una mejor escalabilidad y rendimiento al trabajar con grandes volúmenes de datos de registro. En este caso, bastará con un fragmento, ya que solo tenemos un servidor Graylog y, por lo general, la cantidad recomendada de fragmentos debe ser proporcional a la cantidad de nodos en el clúster.
La retención de los mensajes es de al menos 30 días y luego se eliminan después de 40 días. Personalmente, solo me interesa un mes de datos para ahorrar espacio de almacenamiento, pero puedes definir esto según la cantidad de espacio que tengas para almacenar estos registros que pueden crecer rápidamente en redes con muchos dispositivos.

2. Configuración de búsqueda de servicios y GeoIP
La geolocalización de Graylog es una función que permite a los usuarios mapear datos de registro añadiéndoles información de geolocalización. Graylog viene con capacidades de geolocalización de manera predeterminada, pero se requiere una configuración adicional.
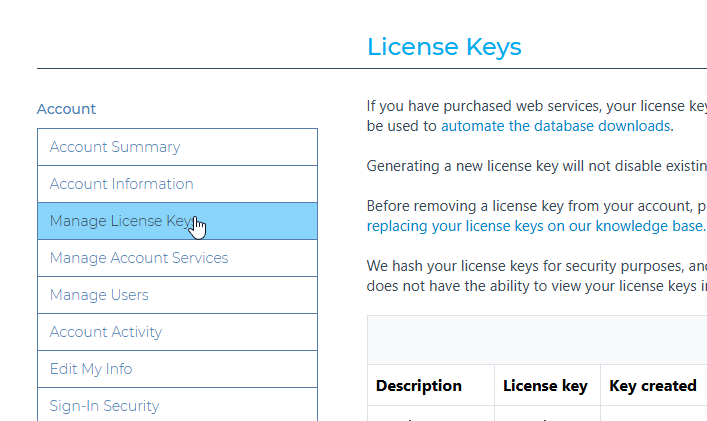
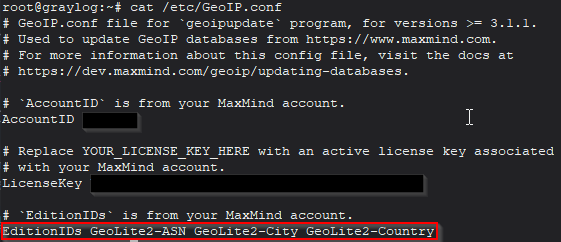
Para comenzar, descargue una base de datos de geolocalización. A partir de la versión 4.3, Graylog admite las bases de datos MaxMind e IPInfo. Creé una cuenta para MaxMind y seguí los pasos Programa de actualización de GeoIP ya que planeamos utilizar su formato de base de datos binaria y esto ayudará a proporcionar actualizaciones automáticas después del trabajo cron creado para esto.
Inicia sesión en tu Maxmind account portal para descargar un archivo de configuración parcial y guardarlo en su directorio de configuración (por ejemplo, /etc/) como GeoIP.conf
Será necesario reemplazar la clave de licencia con un valor de clave de licencia que genere a través del sitio web de MaxMind junto con la actualización de EditionID para incluir Geolite2-ASN si aún no está allí.
 Asegúrese de que su servidor Graylog pueda realizar conexiones HTTPS al siguiente nombre de host:
Asegúrese de que su servidor Graylog pueda realizar conexiones HTTPS al siguiente nombre de host:
mm-prod-geoip-databases.a2649acb697e2c09b632799562c076f2.r2.cloudflarestorage.com
Descargar geoipupdate en su Graylog.
wget https://github.com/maxmind/geoipupdate/releases/download/v7.1.0/geoipupdate_7.1.0_linux_amd64.deb
sudo dpkg -i geoipupdate_7.1.0_linux_amd64.deb
Una vez descargado, puede ejecutar sudo geoipupdate -v para descargar los conjuntos de datos GeoIP más recientes. Los conjuntos de datos se almacenan en /usr/share/GeoIP.
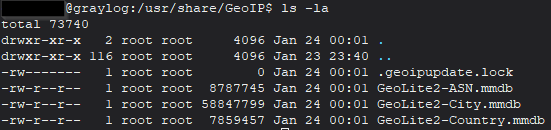
Dado que estoy usando Ubuntu para alojar mi servicio Graylog en mi laboratorio doméstico, podemos configurar un crontab para geoipupdate de modo que ejecute el comando todos los días a las 3 a. m. y almacene cualquier resultado o error en /var/log/geoipupdate.log. Haga lo siguiente:
sudo crontab -e
# Enter at the bottom of root crontab
0 3 * * * /usr/bin/geoipupdate -v > /var/log/geoipupdate.log 2>&1
Luego puedes descargar un CSV desde mi repositorio de Github que uso para búsquedas de servicios de puertos en la siguiente ubicación en su servidor Graylog: /etc/graylog/server/service-names-port-numbers.csv
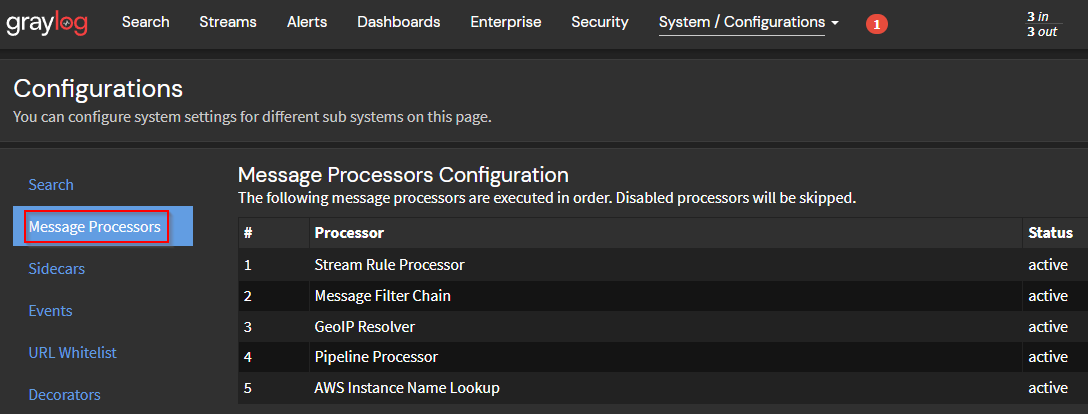
Asegúrese de que el siguiente orden del procesador de mensajes coincida con la configuración de Graylog para que los mensajes se manejen en el orden correcto al analizar los datos:
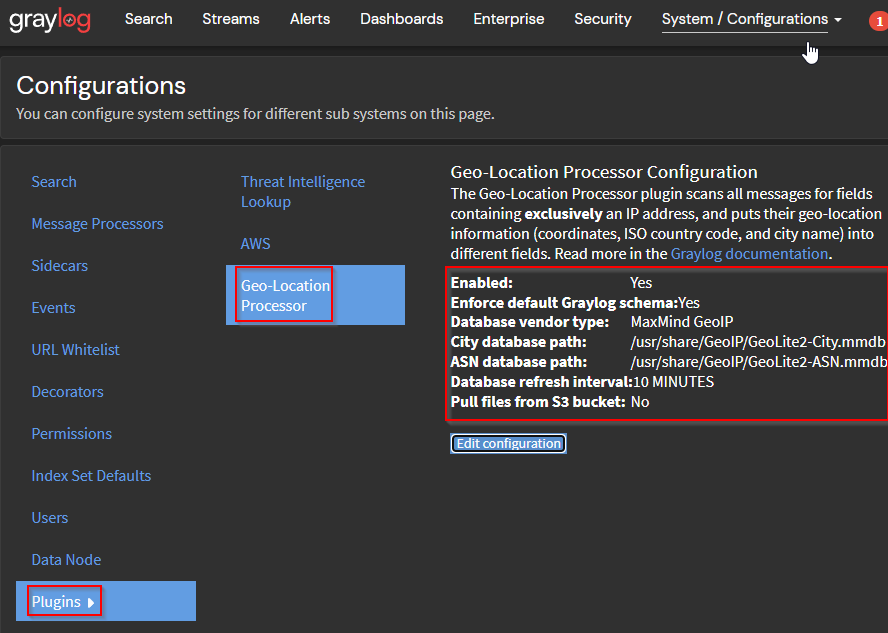
Una vez completadas ambas descargas respectivas, activaremos la base de datos Geo IP en Graylog:
3. Importación de paquete de contenido
Al revisar los mensajes de registro recibidos antes de usar un paquete de contenido, inicialmente notará que el contenido del mensaje no se analiza debido a la necesidad de crear algunos extractores para ayudar a definir los elementos del archivo de registro según un patrón.
La configuración restante de Graylog implica cargar un paquete de contenido que he generado para este proyecto. Este paquete de contenido refleja la configuración de mi laboratorio en casa en el siguiente Github repo. El archivo JSON contiene configuraciones preconfiguradas que crearán automáticamente los componentes restantes para nosotros, incluidos flujos, canalizaciones y reglas de análisis.
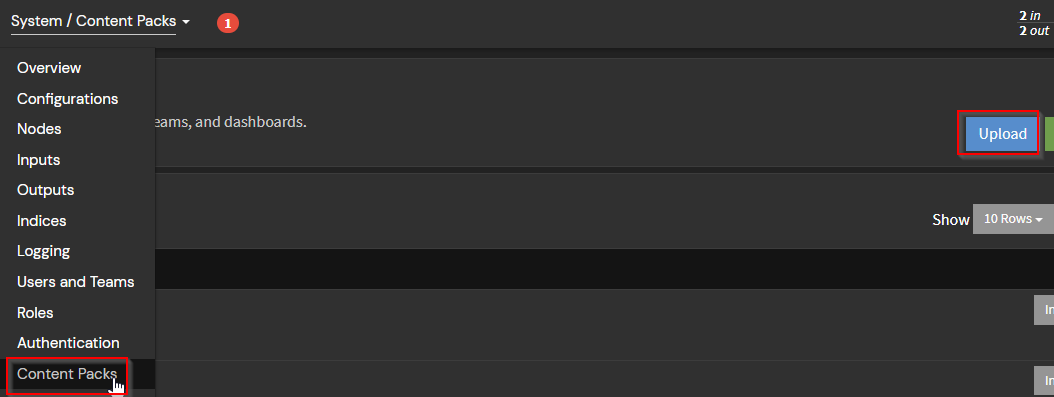
Cuando cargues el paquete de contenido correctamente, verás que el nuevo paquete está listo para instalarse. Luego, puedes instalar el paquete para importar la configuración.
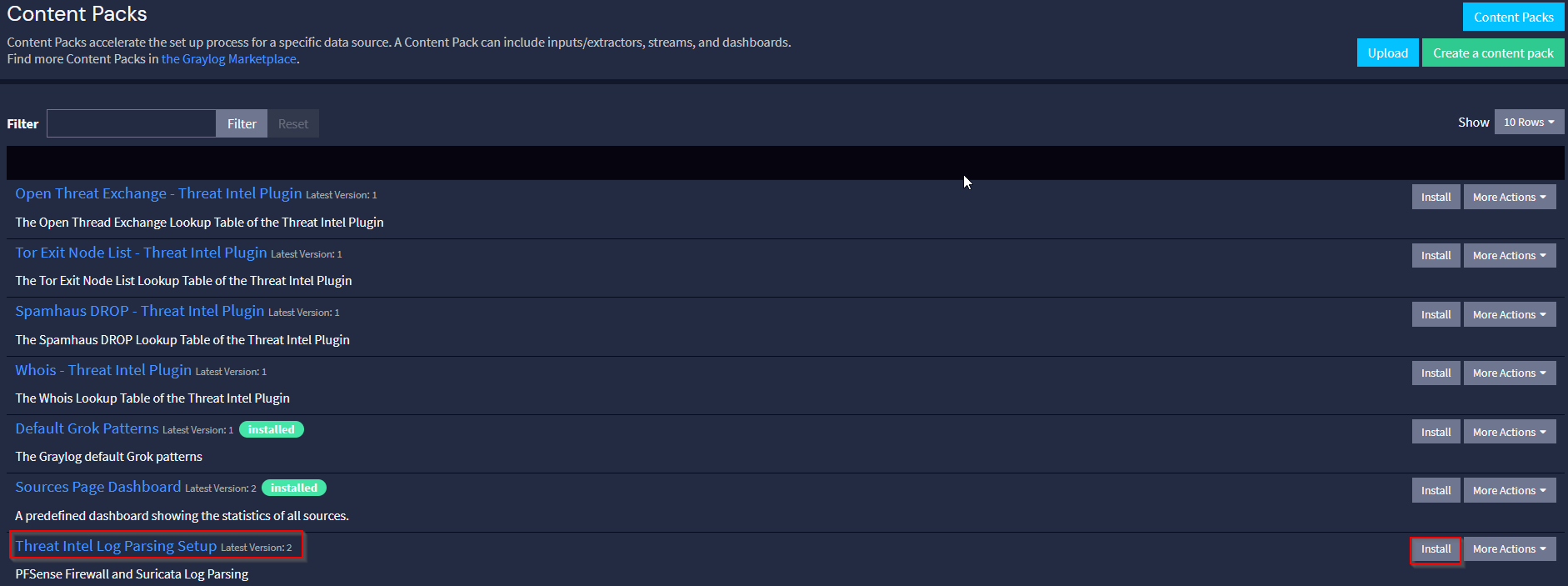

Esto dará como resultado la creación de 3 nuevos flujos junto con la canalización y las reglas respectivas para analizar los mensajes.
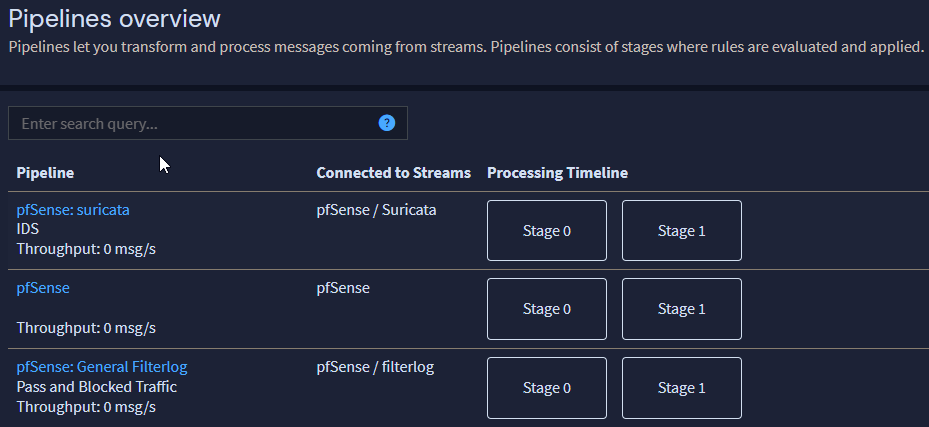
Observe cómo los flujos están configurados actualmente con el índice predeterminado establecido, que deberá cambiar a los índices que creamos en el Inicio de esta entrada del blog para que las configuraciones de retención de registros se apliquen a las transmisiones recién creadas.
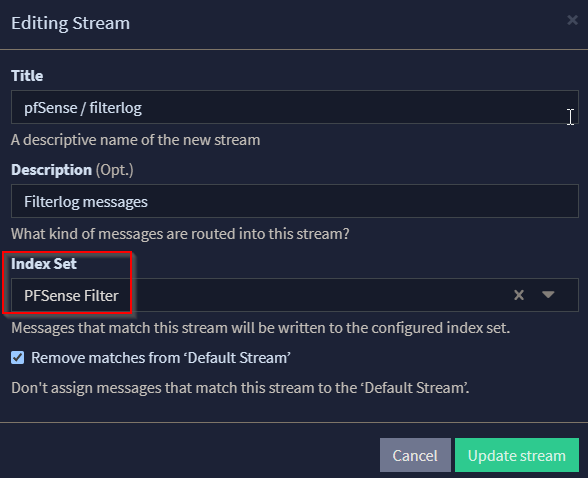
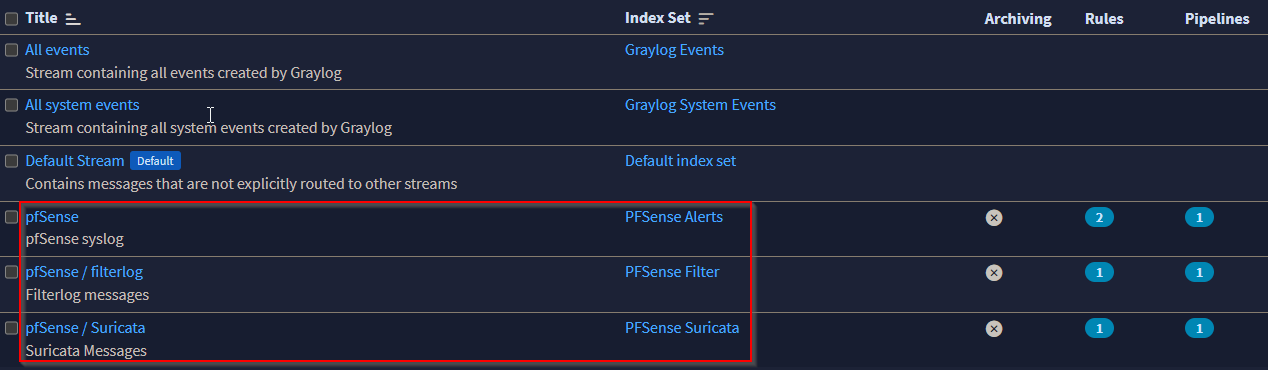
En este punto, puede continuar con la última parte de esta serie, donde instalamos Grafana en nuestra instancia de Graylog y comenzamos a analizar cómo crear paneles con nuestros datos analizados, o puede continuar leyendo a continuación, donde proporciono contexto adicional sobre lo que contiene el paquete de contenido y cómo está todo configurado.
4. Desglose del paquete de contenido
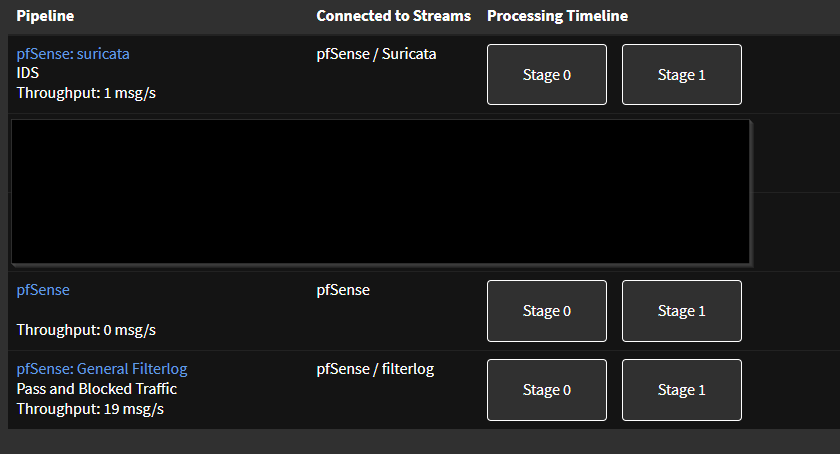
Graylog comienza exponiendo las entradas de varias fuentes de registro. A medida que se reciben los mensajes de registro, Graylog los enruta a flujos específicos. Este proceso de enrutamiento se rige por reglas asociadas con cada flujo, que definen los criterios para determinar qué mensajes deben dirigirse a qué flujos.
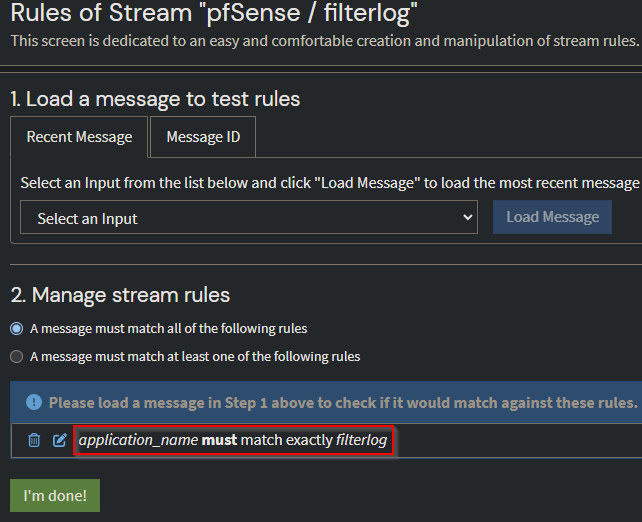
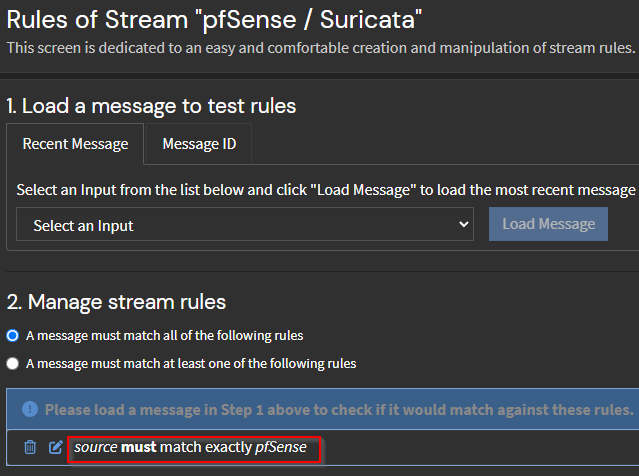
Los pipelines nos permiten transformar y procesar mensajes provenientes de streams. Los pipelines constan de etapas donde se evalúan y aplican las reglas. Los mensajes pueden pasar por una o más etapas. Actualmente tenemos 2 etapas configuradas para cada stream:
- La primera etapa analiza los campos de los mensajes de registro
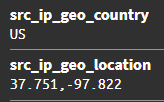
- La segunda etapa implica extraer las direcciones IP de origen de los mensajes de registro. Estas direcciones IP extraídas se utilizan luego para realizar búsquedas de GeoIP y los resultados de la consulta se vuelven a incluir en el mensaje de registro.
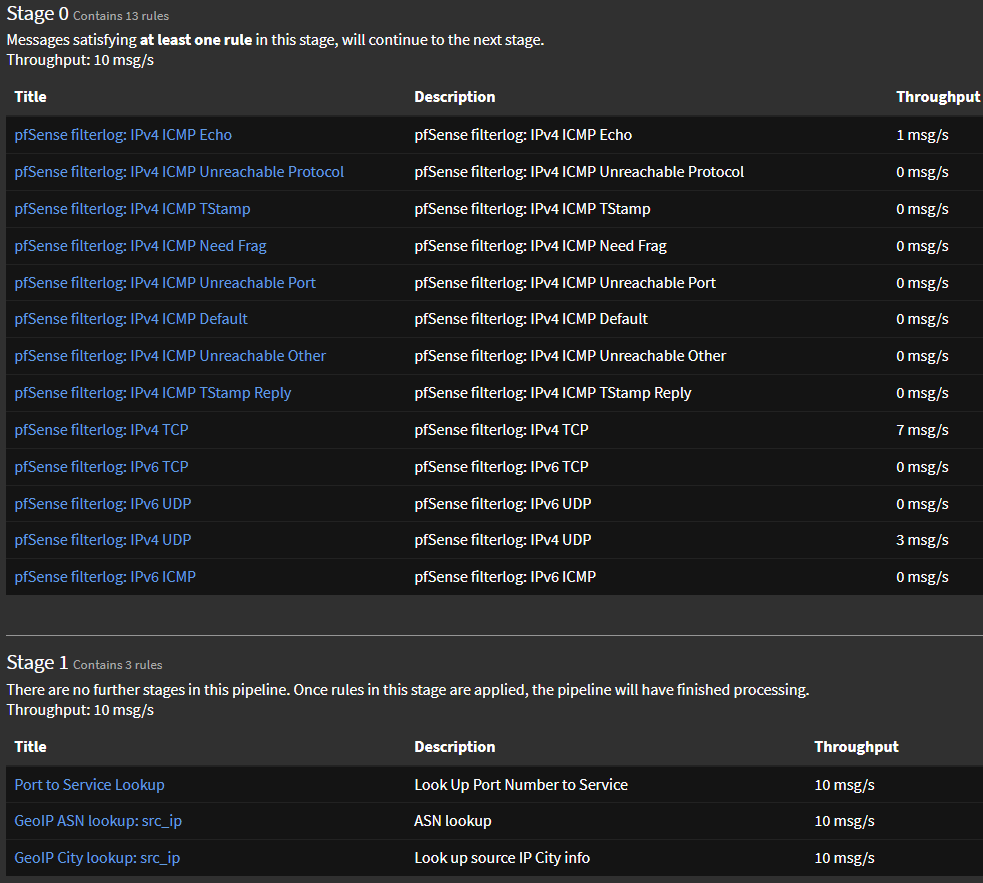
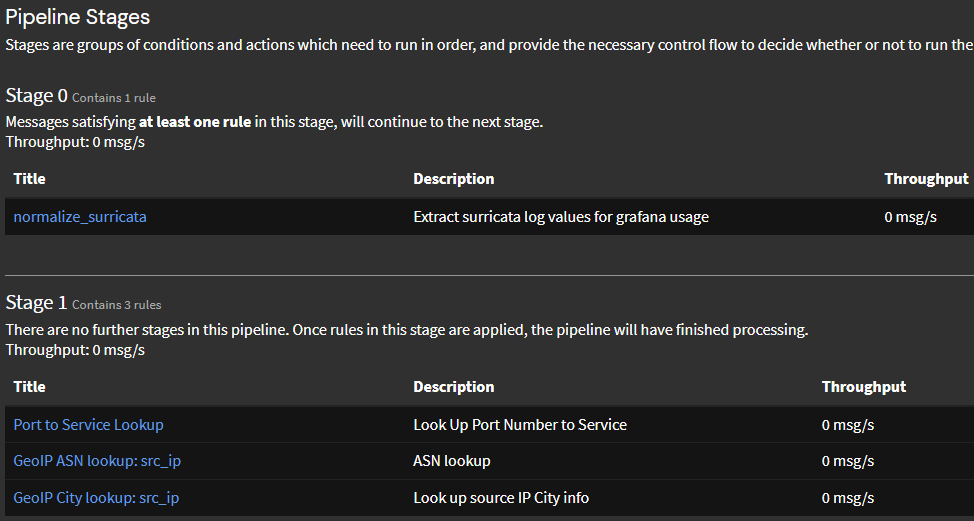
La primera captura de pantalla muestra las reglas de etapa para los registros de filtro general de PFSense, mientras que la captura de pantalla siguiente es para las alertas de Suricata.
Si tiene curiosidad por aprender más sobre cómo escribir la fuente de la regla, consulte Graylog documentation Lo que me ayudó a comprender la estructura y la sintaxis de las reglas para crearlas a través del editor de código fuente en Graylog. ¡Consulta https://pipe-dreams.vercel.app/ para obtener ayuda con la IA!
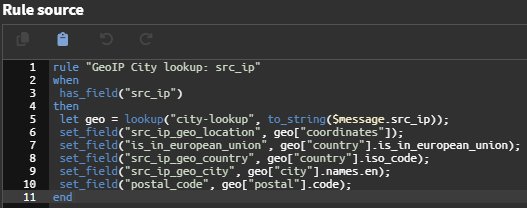
Las tablas de búsqueda se generan y se utilizan en el procesamiento de la canalización para mejorar los mensajes de registro enriqueciéndolos con detalles adicionales y manteniendo un caché de resultados consultados previamente. Este proceso implica agregar el nombre del servicio correspondiente al puerto de destino, así como la ciudad y el número de sistema autónomo (ASN) vinculado a las direcciones IP de origen identificadas en los registros. Estas configuraciones apuntan a la búsqueda de servicios CSV junto con conjuntos de datos GeoIP Lo descargamos en Graylog.
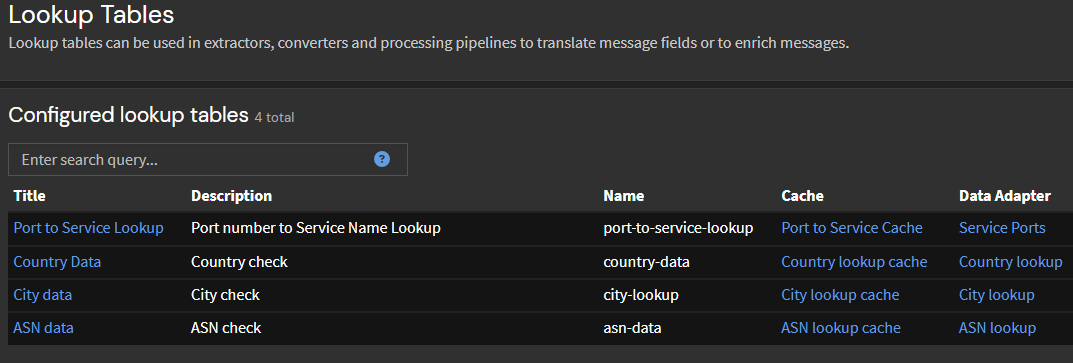
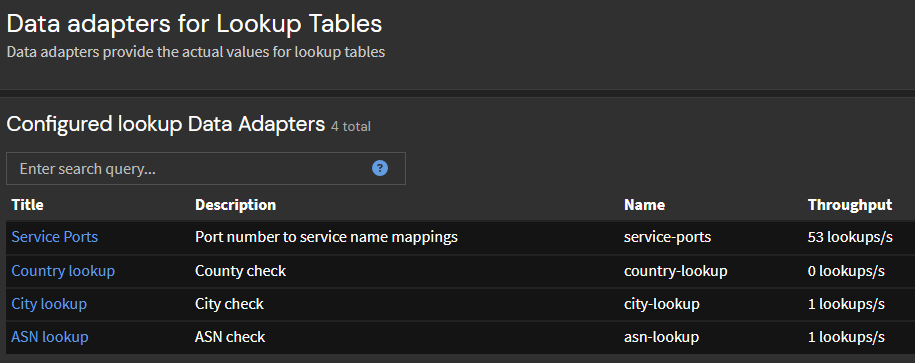
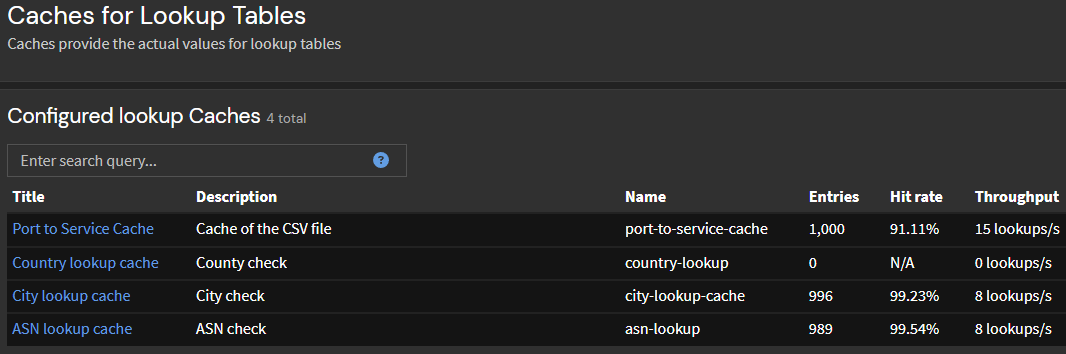
Esto nos permite analizar y graficar la frecuencia de los mensajes recibidos desde el origen de posibles ataques.
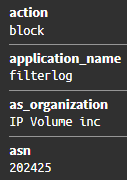
En la siguiente y última parte de esta serie, aprenderemos cómo extraer estos datos de Grafana y visualizarlos.